
Linux 高级编程 - 必备的 gcc 基础
版权声明:本文为 DLonng 原创文章,可以随意转载,但必须在明确位置注明出处!
本文摘要
这篇文章主要介绍 gcc 相关的技术,包括以下 8 个方面:
- gcc 简介
- gcc 参数
- gcc 编译 C 程序 4 个过程
- 实验一:编译多个 C 程序
- 实验二:打包静态库并调用
- 实验三:打包动态库并调用
- g++ 简介
- 结语
我是一个比较强调实践的人,我写的技术文章也是,还希望看完有兴趣一定要实践,出错不可怕,害怕出错才可怕呢。
gcc 简介
GCC(GNU Compiler Collection) GNU 编译器套件,它是 GNU 项目中符合 ANSI C 标准的编译系统,能够编译用 C,C++,Object - C 等语言编写的程序,同时 gcc 也是一个交叉编译器,特别适用于不同平台的嵌入式开发,例如可以在 x86 下编译 ARM 程序。
gcc 规定的部分文件名
gcc 官方规定了下面的一些文件名,有必要了解一下:
- c: C 源程序
- cc/cxx: C++ 源程序
- m: Objective-C 源程序
- i: 预处理的 C 源程序
- ii: 预处理的 C++ 源程序
- s/S: 汇编语言源程序
- h: 预处理头文件
- o: 目标文件
- a: 静态库文件
- so: 动态库文件
HelloWorld
下面以编译 hello.c 为例简单介绍 gcc 的基本使用方法:
// hello.c
#include <stdio.h>
int main(void) {
printf("Hello World\n");
return 0;
}
编译指令:
gcc hello.c -o hello
这句话的意思是编译 hello.c 文件,[ -o ] 指定了编译后的可执行文件名为 hello,之后我们就可以直接执行 hello。当然还有许多复杂的可选项可以使用,下面来做个参数的大体介绍,更复杂的参数用法还需要在实际工作中去总结。
gcc 参数
在使用 GCC 编译器的时候,我们必须给出一系列必要的调用参数和文件名称,如下:
gcc [options] [filenames]
其中 options 是编译器所需要的参数,filenames 是相关的文件名称。
gcc 参数分类
gcc 的参数有很多,我们不需要全部都学会,也没有那个精力,我们先大概看下基本的分类:
- 通用参数
- C 语言参数
- C++ 参数
- Object - C 参数
- 语言无关参数
- 警告参数
- 调试参数
- 优化参数
- 预编译参数
- 汇编参数
- 链接参数
- 机器依赖参数
可以看出类别还是很多的,但是我们平常使用的参数也不是很多,把经常用的学会基本就够用了,不懂的参数可以通过 man gcc 来查找,那下面就来介绍下常用的一些参数。
常用参数
哪些是常用的参数呢?告诉你一个方法,man gcc 手册中前面列出的基本就是常用的了,我总结了下面这些。
1. 编译过程参数
下面几个编译过程比较常见,例如 [-o],[-c],[-l] 等:
[-c]:编译不链接,生成 .o 文件
[-S]:编译不汇编,只生成汇编代码
[-E]:只预编译
[-g]:包含调试信息
[-o file]:指定输出文件名称
[-l dir]:添加头文件路径
2. 动态库和静态库参数
我们经常需要静态编译,打包动态库 .so,这些参数也很有用:
[-static]:让 gcc 静态编译
[-Ldir]:添加搜索库文件的路径
[-shared]:生成动态库文件,用于打包动态库
[-fPIC]:生成位置无关的代码,用于打包动态库
3. 警告参数
我们有时需要开启 gcc 的编译警告来帮我们找找 bug,这时下面的参数就很有用了:
[-w]:关闭所有警告
[-Wall]:发出 gcc 提供的所有有用的警告
[-pedantic]:发出 ANSI C 的所有警告
4. 优化参数
为了让我们的程序运行的更快,在发布的时候经常使用优化参数来优化程序:
-O[level]:优化等级,一般只是项目最后时候才用
了解了常用的参数,下面来学习下 gcc 的编译的大体过程,顺便练习下部分的参数,了解它可以让我们更加清楚编译型语言的编译过程。
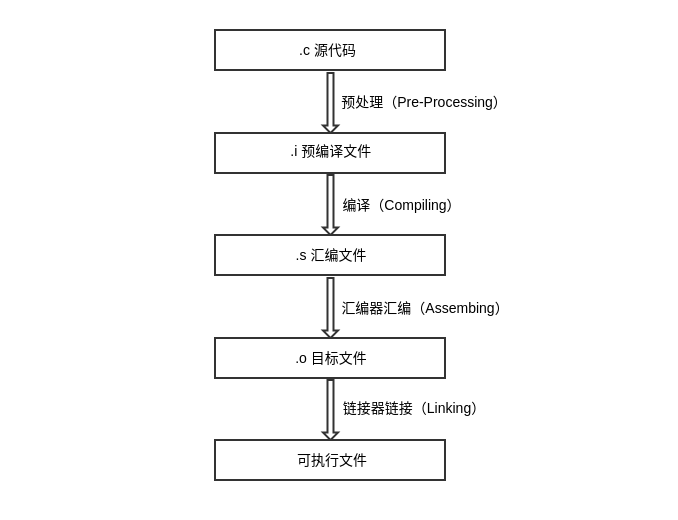
gcc 编译 C 程序的 4 个过程
对于编译型语言,例如 C/C++ 来说,gcc 的编译 hello.c 整体分为以下 4 个步骤:
hello.c源代码经过编译器预处理(Pre-Processing)生成预编译文件hello.ihello.i预编译文件经过编译器编译(Compiling)生成汇编文件hello.shello.s汇编文件经过编译器的汇编器汇编(Assembing)生成目标文件hello.o- 所有的目标文件,这里只有一个
hello.o被链接器链接(Linking)生成最后的可执行文件hello,默认输出的名字是a.out,但是我们指定了输出名为hello
如下图所示:
光说的话还加深不了你的理解,那么我们就来实际编译看看结果怎么样。
1. 预处理 hello.c
使用下面的命令来预处理 hello.c 生成 hello.i:
gcc -E hello.c -o hello.i
预处理就相当于将源文件展开了一样,你可以使用 cat hello.i 查看下里面的内容,因为 hello.i 的内容很多,这里只列出开头的一部分:
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 31 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
...
2. 编译 hello.i
我们使用下面的命令来将 hello.i 编译成 hello.s:
gcc -S hello.i -o hello.s
我们看下 hello.s 的内容,这里也只列出一部分,都是汇编代码:
.file "hello.c"
.section .rodata
.LC0:
.string "Hello World"
.text
.globl main
.type main, @function
main:
.LFB0:
...
3. 汇编 hello.s
我们使用下面的命令来将 hello.s 汇编成 hello.o 目标文件:
gcc -c hello.s -o hello.o
这时候生成的 hello.o 就是二进制的文件了,我们可以看看它的开头部分内容,可以看到在我的 Ubuntu 上显示是 「ELF(Executable and Linkable Format) 可执行链接文件格式」的文件,说明这个文件可以被链接:
ELF>�@@
UH��H�=��]�Hello WorldGCC: (Ubuntu 6.2.0-5ubuntu12) 6.2.0 20161005zRx
下面就进行最后一步,链接 hello.o。
链接 hello.o
我们使用下面的命令来将 hello.o 链接成最后的 hello 可执行文件:
gcc hello.o -o hello
然后可以执行了:
./hello
# 结果
Hello World
至于可执行文件 hello 的内容,你应该是知道的,因为它是由多个目标文件链接而成的,既然目标文件是二进制的,毫无疑问可执行文件肯定也是二进制的,不信给你看看 hello 的开头:
^?ELF^B^A^A^@^@^@^@^@^@^@^@^@^C^@>^@^A^@^@^@p^E^@^@^@^@^@^@@
^@^@^@^@^@^@^@?^Y^@^@^@^@^@^@^@^@^@^@@^@8^@ ^@@^@^]^@^Z
你看的懂不,我反正是看不懂 :),不过不要紧,知道他是编译最终生成的二进制可执行程序即可。
当你成功打印出 Hello World 说明你已经成功将整个编译过程分步骤完成了,了解了这个分步的编译过程,可以更好的使用 gcc,因为你知道 gcc 在编译 hello.c 的时候每一步大概做了些什么,使用起来更加有信心了,这也是了解一些原理的必要性。
实践:3 个使用 gcc 的实验
实践是检验真理的唯一标准,写程序这个东西光看看怎么行,不动手基本就是过眼云烟,那些能够在看完博客之后立马去实践的人才能进步的更快。废话不多说,下面就介绍 3 个基本的使用 gcc 来编译程序的实验,这 3 个实验都用到下面 2 个文件:
这个文件是含有 main 的主程序文件:
// main.c
#include <stdio.h>
// 声明 add 函数在外部有定义,不加声明会产生警告
extern int add(int a, int b);
int main(void) {
printf("%d\n", add(1, 2));
return 0;
}
这个文件里面只有一个 add 函数:
// add.c
int add(int a, int b) {
return a + b;
}
先来看最简单的第一个实验吧。
1. gcc 编译两个程序相互调用
这个实验要求是这样的:让 main.c 调用 add.c 里面的函数,那么如何使用 gcc 来编译他们呢?
我们前面已经了解了 gcc 编译程序的 4 个基本步骤,知道每个源文件最后都会被编译成目标文件,然后被链接器链接到一起生成最后的可执行文件,因此可以推断出编译器先分别生成 main.o 和 add.o 然后将他们链接到一起生成最后的可执行文件,所以编译命令如下:
gcc main.c add.c -o main
直接将这两个文件一起编译即可,然后执行:
./main
# 1 + 2 = 3
3
输出 3 则表明你第一个实验已经成功了,是不是很简单,别放松,来看第二个实验。
2. gcc 编译静态库并调用
在 Linux 我们经常调用别人给我们提供的静态库,静态库本质上就是一系列函数的二进制表示的集合,不过不包含 main 函数,因此只能作为模块提供给别人使用,静态库名称通常为 libname.a。下面就来介绍如何将 add.c 打包成一个静态库来供 main.c 来调用,一共有 3 步:
编译出 add.o
因为静态库里面都是已经编译好的函数,因此我们需要先将 add.c 编译成可以链接的 ELF 格式的目标文件:
gcc -c add.c -o add.o
ar 打包静态库
我们使用 ar 这个命令来将 add.o 打包成 libadd.a,参数 [-crv] 记住即可,如需了解直接 man ar,注意文件的顺序哦,静态库文件名在前,目标文件在后,我实验的时候都搞错了 = =:
ar -crv libadd.a add.o
使用静态库 libadd.a
那么如何将一个静态库在编译的时候静态链接到 main.c 的模块上呢,使用下面的命令,[-L./] 表示将当前目录加到静态库的搜索路径:
gcc main.c -L./ libadd.a -o main
之后执行,输出 3 表明成功调用 libadd.a 里面的 add 函数了:
./main
# 1 + 2 = 3
3
静态库实验其实就 3 步,不是很复杂,动态库也不难,一起来看看吧。
3. gcc 编译动态库并调用
动态库与静态库有些异同:
- 相同:动态库也是函数的二进制的集合
- 不同:动态库在程序运行的时候动态加载到内存,而静态库在编译时期就整合到最后的可执行文件中
之所以叫动态库,就是因为它能够在一个程序运行的时候动态的加载到内存中,这个动态库在内存中也是共享的,在 Linux 下动态库的常用名称为:libname.so.主版本号.次版本号.发行号,关于动态库的其他特点不是本次介绍的重点,需要了解的可以去 Google 搜索,下面还是介绍如何打包和使用一个动态库,分为 4 个步骤:
编译位置无关的目标文件 add.o
为何需要编译位置无关呢?因为动态库动态加载到内存中的位置是不确定,所以需要位置无关,使用 [-fPIC] 来编译出一个位置无关的目标文件:
gcc -fPIC -c add.c -o add.o
打包成动态库
使用下面的命令来将 add.o 打包成 libadd.so 动态库,这里就不加版本号了:
gcc -shared add.o -o libadd.so
链接到 main.o
这里的链接不是实际的链接,这里只是告诉 main.o 在运行的时候需要动态加载 libadd.so 这个动态库而已:
gcc main.c -L. libadd.so -o main
运行 ./main
注意,如果你直接执行 ./main 的话,你应该会得到下面这个错误:
./main: error while loading shared libraries: libadd.so: cannot open shared object file: No such file or directory
这是为什么呢?你可能会想我不是将 libadd.so 告诉了 main.so 了么,为何还报错误,其实这个错误的原因是:main 运行时,当要加载 libadd.so 这个动态库时,没有找到它。为何没有找到?因为你没有将这个动态库加到系统的环境变量指定的目录中。
如何解决这个错误呢?
解决方法:将 libadd.so 拷贝到系统的库目录下:
sudo cp libadd.so /usr/lib/libadd.so
之后再执行:
./main
# 1 + 2 = 3
3
如果成功的打印出了 3,则说明已经成功调用了动态库了。
这样,我们就了解了如何相互调用程序,如何打包并调用静态库和动态库这 3 个实验,还希望你一定要亲自动手去实践下,这其中每一个命令我都有亲自验证过,把这些东西都变为自己的,相信我,你肯定会有很大收获的。
介绍完了 gcc,不能不了解下它的好朋友 g++ 啊,再一起简单了解下吧,有谁会嫌弃自己懂得多呢,你说 4 不 4 :)
g++ 简介
既然编译 C 语言用 gcc ,那编译 C++ 用 g++ 可以说是很恰当的表达方法了,下面看看如何编译一个 C++ 的 hello.cc 吧,跟 gcc 编译 C 语言几乎相同:
// hello.cc
#include <iostream>
int main(void) {
std::cout << "Hello World" << std::endl;
return 0;
}
使用下面的命令来编译:
g++ hello.cc -o hello
是不是几乎相同,但这篇文章的重点不是 g++,就简单介绍到这吧,有兴趣的可以去查找相关的资料。
结语
实践是检验真理的唯一标准!
这篇文章主要介绍了一些 gcc 的基础知识,比如编译,如何打包静态库,如何打包动态库,这些还是比较常用的操作,希望看完一定要实践,之后我会再写一片关于如何编译 gcc 的文章,有兴趣的可以关注更新。
谢谢你的阅读 :)
DLonng at 07/19/17