
Linux 高级编程 - 无名管道 Pipe
版权声明:本文为 DLonng 原创文章,可以随意转载,但必须在明确位置注明出处!
Linux 进程间通信
当系统中有了多个进程时,进程之间的通信就显得格外必要了,进程就相当于现实世界中的人,人跟人之间的交流就相当与进程之间的通信了。Linux 的进程间通信(Inter Process Communication,IPC)主要有 7 种:
- 无名管道
Pipe - 有名管道
Fifo - 信号
Signal - 消息队列
Message Queue - 共享内存
Share Memory - 信号量
Semphone - 套接字
Socket
这 7 种方式有各自的适用场合。在早期管道和信号是用于单机 IPC 的主要方式,在后来 AT&T 的贝尔实验室在那之上又拓展了一个 System V IPC,其中包含了共享内存,消息队列,信号量这 3 种方法,再之后 BSD(加州大学伯克利分校软件研发中心)开发了套接字用来进行网络通信,从这也可以得出网络通信其实就是不同机器之间的进程相互通信,本质上还是属于进程间的通信,只不过多了一个网络的桥梁而已。这就是整个 IPC 的发展过程,IPC 是 Linux 中的一个非常重要的模块,必须掌握这 7 种方式,这也是面试必问的东西。
这篇文章主要介绍第一种 IPC 的机制:无名管道 Pipe,并且会分析它在 Linux 内核的实现机制,废话不多说,赶紧上车…
什么是无名管道 Pipe?
shell 管道
管道是 UNIX 系统 IPC 的最古老的形式,所有的 UNIX 系统都提供管道机制,如果你使用过 shell 中的管道,应该不会默认,例如:
ps -aux | grep "xxx"
这个意思是将 ps -aux 的输出作为 grep xxx 的输入,通过管道可以将两个进程连接起来,功能非常强大,但是有名管道与 shell 的管道有些区别。
无名管道
有名管道具有下面 3 个特点:
- 只能用于有亲缘关系(父子进程)的进程间通信
- 半双工通信方式,具有固定的读写端
- Pipe 被当作特殊文件来对待(Linux 下一切都是文件)
需要了解下半双工和全双工的区别:
- 半双工:同一时刻,数据只能往一个方向传输
- 全双工:同一时刻,数据可以往两个方向传输
有名管道是半双工的,每个时刻一个进程只能读取或者写入,即只能打开读端口或者写端口,不可同时打开。下面的图可以更好地解释在父子进程之间使用管道的模型:
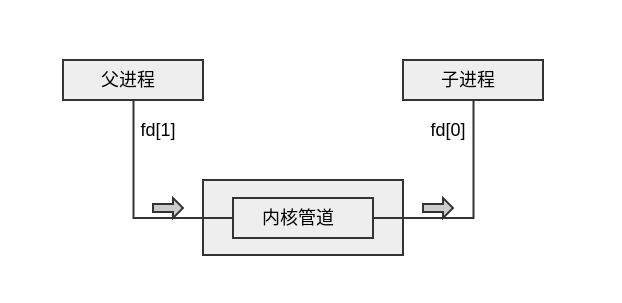
这个模型中内核有一个管道的缓冲区,父进程将数据写入管道写端(fd[1]),子进程从管道读端(fd[0])中读取数据。
例子:test_pipe.c
了解了有名管道的基本原理,下面我们使用 pipe 来创建一个管道,这是 pipe 函数定义:
#include <unistd.h>
/*
* fd[0]:用于读取
* fd[1]:用于写入
* return:成功返回 0, 失败返回 -1,并设置 erron
*/
int pipe(int pipefd[2]);
这个例子中我们在父进程中 fork 了一个子进程,在 fork 之后要做什么取决与我们想要的数据流的方向,这里设置子进程从父进程读取数据,所以需要关闭子进程的写端 fd[1] 和父进程的读端 fd[0],注意无名管道不能同时读写。
// test_pipe.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
int pfd[2];
int pid;
int status = 0;
char w_cont[] = "Hello child, I'm parent!";
char r_cont[255] = { 0 };
int write_len = strlen(w_cont);
// 创建管道
if(pipe(pfd) < 0) {
perror("create pipe failed");
exit(1);
} else {
// 创建子进程
if((pid = fork()) < 0) {
perror("create process failed");
} else if(pid > 0) {
// 关闭父进程读端
close(pfd[0]);
// 父进程像写端写入数据
write(pfd[1], w_cont, write_len);
close(pfd[1]);
// 等待子进程结束
wait(&status);
} else {
sleep(2);
// 关闭子进程写端
close(pfd[1]);
// 子进程从读端读取数据
read(pfd[0], r_cont, write_len);
// 子进程输出读取的数据
printf("child process read: %s\n", r_cont);
}
return 0 ;
}
编译运行看看:
gcc test_pipe.c -o test_pipe
./test_pipe
child process read: Hello child, I'm parent!
可以看到子进程成功读取了父进程写入的数据,整个过程一共分为 6 个步骤:
- 创建管道
- 创建子进程
- 父进程关闭读端,向写端写入数据
- 子进程等待 2s,等父进程写入完毕
- 子进程关闭写端,从读端读取数据并输出
- 父进程用 wait 等待子进程结束
这个例子可以很好的解释管道的使用方法:父进程写入,子进程读取,当然你也可以设置子进程写,父进程读,只要改变进程的读写端口和代码逻辑即可,代码参考:test_pipe.c,test_pipe2.c
Pipe 的内核实现
管道的操作比较的简单,为了更好的理解它的原理,我们看看 Linux 内核中的管道是如何实现的,因为不同版本的 Linux 内核中的修改比较大,这里以 Linux-3.4 版本来分析。
Pipe 注册过程
内核的 Pipe 的实现原理大体上如下:Pipe 将内存中一片区域映射到虚拟文件系统 VFS,使得上层应用可以像操作文件那样来操作 Pipe,从而实现 IPC,也就是说 Pipe 是以管道文件系统为基础的,我们来看看 fs/pipe.c 中的 pipe 文件系统的注册过程,实际上就是一个驱动程序:

这个过程向内核注册了 pipe 的文件系统,这个文件系统也受 VFS 的控制。
Pipe 的调用过程
再来看看管道的调用过程,上层的 pipe 调用一般都对应底层的 sys_pipe 调用,但是随着内核的修改,有些名称会改变,比如 sys_pipe 在 3.4 中就是用宏定义来表示的:
/*
* fs/pipe.c
* sys_pipe() is the normal C calling standard for creating
* a pipe. It's not the way Unix traditionally does this, though.
**/
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
int fd[2];
int error;
error = do_pipe_flags(fd, flags);
if (!error) {
if (copy_to_user(fildes, fd, sizeof(fd))) {
sys_close(fd[0]);
sys_close(fd[1]);
error = -EFAULT;
}
}
return error;
}
这是具体的执行过程:
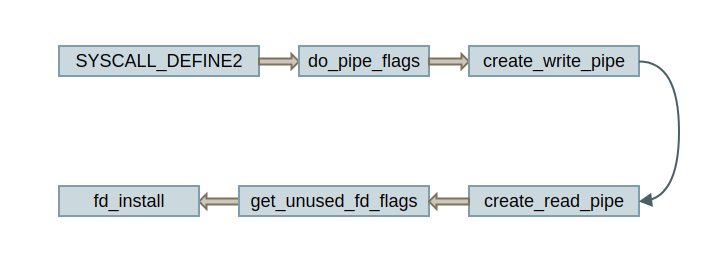
这个过程所做的事情主要是向内核申请内存,创建读写描述符,以此建立 pipe 文件。其中比较重要的是 create_write_pipe,这个函数创建一个写管道,在最后调用 kzalloc 向内核申请内存空间:
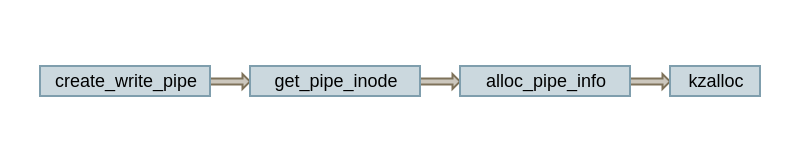
这也印证了 pipe 将内存中一片区域映射成虚拟文件系统以及 Linux 的进程间通信实质上就是 IO 操作这两个概念。
结语
本次,我们了解了 Linux 下进程间通信(IPC)的 7 种方式,并着重学习了第一种方式:无名管道 Pipe。管道是最古老的 IPC 方式,使用起来也比较简单,并且我们也简单分析了内核中对 pipe 的实现过程,知道了 pipe 其实也是以文件 IO 的方式来实现 IPC 的,了解些内核的机制可以让我们对 IPC 有一个更好的理解。
感谢你的阅读,我们下次再见 :)
本文原创首发于微信公号「登龙」,分享机器学习、算法编程、Python、机器人技术等原创文章,扫码即可关注!

DLonng at 08/05/17