
从 0 开始机器学习 - 线性回归 & 代价函数 & 梯度下降
一、机器学习问题解决流程

二、第一个机器学习问题:单变量线性回归
2.1 问题描述
这个线性回归算法就是高中学的最小二乘拟合曲线数据点,通过下面这个例子来复习下机器学习算法工作流程,根据房屋面积预测出售价格(监督学习):
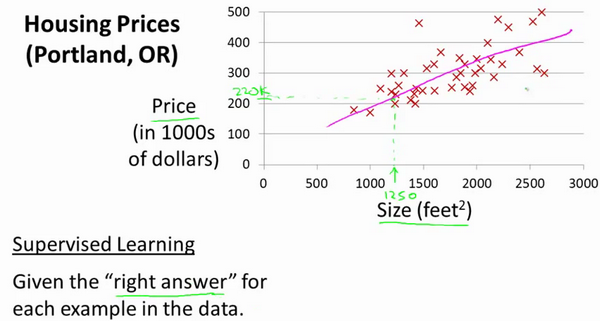
2.2 训练数据集
训练数据集如下(训练就是用给定的数据来计算最优的函数曲线参数,使得拟合效果最好):
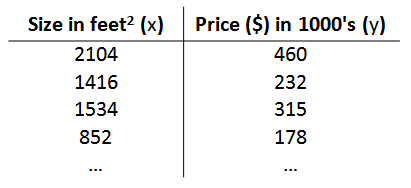
- m 代表训练集中实例的数量
- x 代表输入变量(特征 Feature)
- y 代表输出变量(目标变量)
- (x, y) 代表训练集中的实例
- (Xi, Yi) 代表第 i 个观察实例
- h 代表学习算法的解决方案或函数,也称为假设函数(hypothesis)
2.3 模型选择及总结
使用训练数据集和选择的训练算法,来计算假设函数 $h$ 的参数,使得给定一个输入,假设函数给出一个预测的输出:
- 训练集:人为标记的房屋面积和对应房价的一组数据点
- 学习算法:梯度下降法
- 输入和输出:房屋的预测价格 $y = h$(房屋面积 x)
- 假设函数 $h$: $h_\theta \left( x \right)=\theta_{0}+\theta_{1}x$,线性函数拟合
机器学习算法的训练就是计算最优的参数 a 和 b,这里的函数只有一个输入特征面积,所以叫单变量线性回归模型。
三、代价函数(Cost Function)
我的理解:代价函数(cost function,loss function)在机器学习中的作用是确定最优的函数参数,使得拟合数据点的误差达到最小,即拟合效果最好。
因为我们训练函数参数,最终还是要选择一个最优的,那么代价函数就给我们一个最优参数的度量方式,使得我们可以根据数学理论选择训练参数。
3.1 预测房价的代价函数
还是用预测房价的例子来介绍下代价函数的原理,这是预测房价的数据集:

我们使用线性回归算法来预测,所以取假设函数 Hypothesis 的表达式为 2 个参数($\theta_0$,$\theta_1$)线性函数,那么这个机器学习的问题就可以转换为如何选择最优的参数来使得预测的误差(代价)最小?
可问题是用什么方式来度量预测的误差呢?这时代价函数就派上用场了,我们可以用代价函数来计算不同参数所对应的误差,取误差最小的那组参数作为训练的最终结果,代价函数有挺多种形式,线性回归常用误差的平方和计算代价:

上面的代价函数 Cost Function 的求和公式其实就是高中学习的最小二乘法的平方误差的计算,最终的求和结果就是预测值与真实值误差的平方和,再除以训练集实例数量,不过要注意这里的乘以 1/2,只是为了尽量把最后的求和结果变小一点,不含有其他逻辑。
可以将 Cost Function 的求和值理解就是下图中三条蓝色线段的长度平方之和再除以 1/ 2m,表示当前预测的函数值与实际的函数值之间的总的误差:
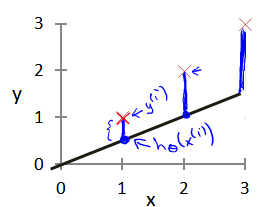
可以直观的理解,蓝色的线段总长度越小(误差越小,代价越小),则预测的函数直线就越接近(1,1)(2,2)(3,3)这 3 个点,且当代价函数的值为 0 时,预测的函数直线就是 y = x(浅蓝色直线),直接拟合了这 3 个训练的数据点,这时误差达到最小,对应的函数参数为 $\theta_0$ = 0,$\theta_1$ = 1,这就是训练的最终结果了。
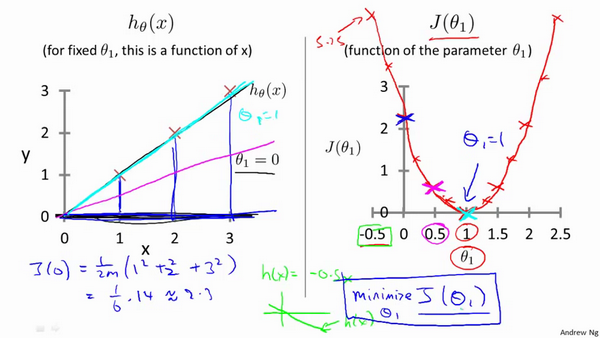
所以机器学习的训练就是找到使得代价函数取最小值得那组参数,就这么简单,听起来挺高大上的,上图中右边的代价函数 $J(\theta_0)$ = 0,但如果不把 $\theta_0$ 设置为 0,又如何理解带有 2 个参数的代价函数呢?继续往下看。
3.2 理解 2 个参数的代价函数
上面一个参数 $\theta_1$ 的代价函数容易理解,如果是两个参数的 $J(\theta_0, \theta_1)$ 的代价函数,函数图形稍微复杂些,不过也不是很难理解,我们目前只需要理解 2 个参数成本函数的求最小值的过程就行了,其他的暂时不需要深究。
来看下这个 2 参数的代价函数,其实就是在参数 $\theta_1$ 的基础上,纵向扩展了一个 $\theta_0$ 维度,最后的曲线变成了一个像渔网一样的图像,我们称这样的函数为凸函数,不必追究它的概念,只需要知道凸函数只有一个局部最优解 - 即渔网的最底部。
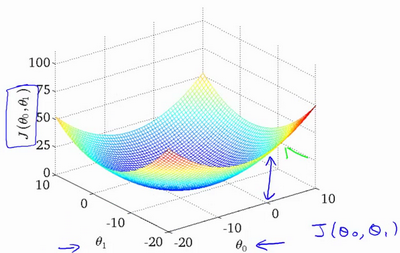
但这个渔网一样的曲线也不是很直观,为了在二维坐标系中显示这个曲线,我们使用等高线来表示这 2 个参数,可以把上面的渔网从下往上看,像个小山头,下面右图就相当于山头的等高线,每个等高线上函数的代价都相同。
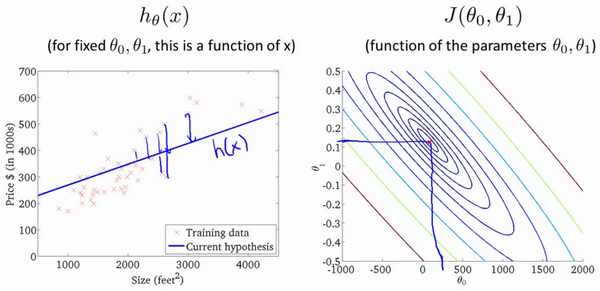
当代价函数达到最小时:
- 渔网图像中($\theta_0$,$\theta_1$)在渔网的最底部取得,使得代价函数达到最小值;
- $h_\theta \left( x \right)$ 图像中预测的函数曲线对训练数据的拟合效果达到最优;
四、梯度下降算法(Gradient Descent)
如何在程序中求代价函数的最小值呢?可以使用经典的梯度下降算法,迭代求代价函数 $J(\theta_0, \theta_1)$ 的最小值。
4.1 算法思想
梯度下降基本思想:开始时随机选择一个参数的组合 $\left( {\theta_{0}},{\theta_{1}},……,{\theta_{n}} \right)$,计算代价函数,然后寻找下一个能让代价函数值下降最多的参数组合,持续这么迭代直到求出一个局部最小值(local minimum)。
但是因为没有尝试完所有的参数组合,所以不能确定得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值(下图中的 2 个谷底就是不同的局部最小值)。
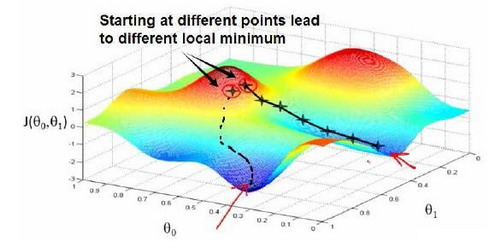
可以拿下山的例子来形象地理解梯度下降:想象一下你正站立在山顶的某一点上,我们要做的就是原地旋转 360 度,看看我们的周围,并问自己如果要在某个方向上用小碎步尽快下山,那么这些小碎步需要朝什么方向?如果我们发现最佳的下山方向,就迈出一步,然后再看看周围,想想我应该从什么方向下山?依此类推,直到你接近局部最低点的位置。
你也可以把这个算法记成梯度下山算法,帮助你更好的理解算法的执行逻辑,但还是要记住原名。
4.2 算法数学理解
在实际算法中,常用批量梯度下降算法(Batch Gradient Descent)来同时更新多个参数 $\theta_i$:

解释下这个更新公式:
- $\theta_j$ 是待更新的参数 ($\theta_0$,$\theta_1$)
- $\alpha$ 是学习率(learning rate),决定了代价函数在下降方向每次更新的步长(其实就是每次下山的小碎步)
- $\alpha \frac{\partial }{\partial {\theta_j}}J(\theta_0,\theta_1)$ 是代价函数对($\theta_0$,$\theta_1$)的偏导数
- 因为是求偏导,所以($\theta_0$,$\theta_1$)必须同步更新
可以用一句话总结这个公式:在批量梯度下降中,每一次同时让所有参数减去学习率 $alpha$ 乘以代价函数的偏导数。
4.3 算法的直观理解
下面用实际的预测房价的代价函数曲线来直观理解梯度下降寻找最优解的执行过程:${\theta_{j}}:={\theta_{j}}-\alpha \frac{\partial }{\partial {\theta_{j}}}J\left(\theta \right)$
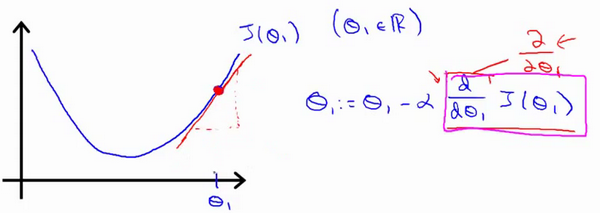
为了方便理解,上面的代价函数假设 $\theta_0$ = 0,红色的直线线表示 $\theta_1$ 点的切线,切线斜率即右端的红框中的对 $\theta_1$ 的偏导数,且切线的斜率大于 0,所以一次更新过程为:新的 $\theta_1$ = 旧的 $\theta_1$ - $\alpha$ * 正数。
影响梯度下降算法的一个重要变量是 $\alpha$,它对更新会产生如下作用:
- 如果 $\alpha$ 太小,每次更新的步长很小,导致要很多步才能才能到达最优点;
- 如果 $\alpha$ 太大,每次更新步长很大,在快接近最优点时,容易应为步长过大错过最优点,最终导致算法无法收敛,甚至发散;
虽然 $\alpha$ 会对更新步长产生影响,但是实际设计算法时,并不需要对 $\alpha$ 进行特殊处理,为什么呢?来看下面这个例子:
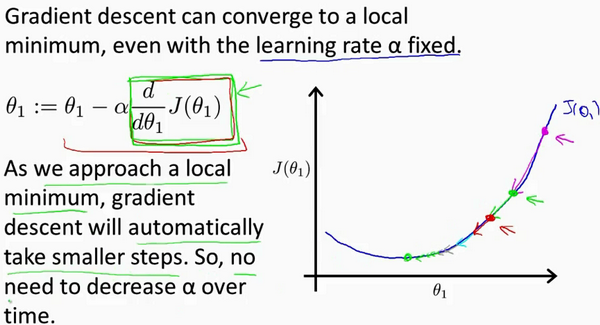
我们知道一点的切线越陡则斜率($\alpha$)越大,越缓则斜率($\alpha$)越小(这里只强调斜率大于 0,斜率小于 0 完全类似,只不过变了符号而已),在上图中随着算法不断迭代,更新的数据点越来越接近曲线底部,相对应的切线也越来越缓,即学习率 $\alpha$ 会自动变小,随着学习率变小,那么下一步更新的步长也就随之变小,因为下一步更新的步长使用的 $\alpha$ 在上一步中已经自动变小了,所以直到下降到最低点(该点导数为 0)时:新的 $\theta_1$ = 旧的 $\theta_1$ - $\alpha$ * 0 = 旧的 $\theta$,此时不再进行迭代,算法找到最优解!
可以看出,梯度下降算法在执行过程中会自动更新 $\alpha$,所以没必须另外再减小 $\alpha$,这点一定要注意了!那么既然学习了梯度下降算法,下面来看看如何用它来找到预测房价的代价函数最优解!
五、梯度下降的线性回归
我们用梯度下降算法来求平方误差代价函数的最小值,以此来拟合房价预测的函数直线,两个部分的公式如下:

当你理解了梯度下降算法的公式后,便可以看出求解的关键点就在于求出代价函数关于参数 $\theta_i$ 的偏导数,求偏导是高数中很基础的方法,这里就不介绍了,直接看下求出的 2 个偏导数:

当我们在程序中求出了所有参数的偏导数后,接着就可以按照算法的逻辑来同步更新参数 $\theta_i$,再一步步迭代下去直到找到最优解。
要注意一点,因为这里代价函数求出的偏导,在计算时需要使用到所有的训练集,因为它含有求和公式,需要累加所有训练数据的误差,所以这里的梯度下降算法也称为批量梯度下降,其中批量的意思就是每次梯度下降时都会用到所有的训练样本。
实际上也有其他不是批量型的梯度下降法,每次迭代值关注训练集中的一个子集,以后我学到了再跟你分享吧,记得持续关注我哈哈哈哈。
本文原创首发于微信公号「登龙」,分享机器学习、算法编程、Python、机器人技术等原创文章,扫码即可关注!

DLonng at 03/21/20