
北理工 MOOC - 模式识别系统基本概念
版权声明:本文为 DLonng 原创文章,可以随意转载,但必须在明确位置注明出处!
最近在 MOOC 上学习北理工的模式识别课程,这里记录下学习笔记。
样本、特征与特征空间
- 样本:一个个具体要识别的事物称为样本。
- 特征:从样本中抽取能够识别这个样本的关键特性,称为样本的一个特征,例如 4 个轮子是汽车的一个重要特征。
- 特征空间:当我们找到一组特征来表达一个样本后,就完成了样本到特征表达之间的数学转换,所有样本转换完后构成的特征表达就是特征空间。
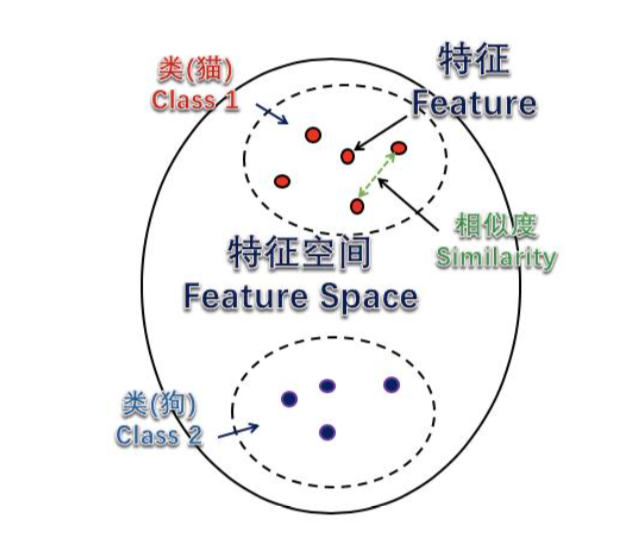
在特征空间中,每个样本都可以看做是由一组特征来表达的一个点,通过抽取样本的特征,并转换成数学表达,就将原事物(样本)的识别问题转换为:对该样本在特征空间中对应点的进行分类。
向量空间、集合空间
- 向量空间:如果样本的一个特征可以抽象成向量的一个维度,那么一个样本的多个特征就可以抽象成向量空间的一个向量,即特征向量。
- 集合空间:如果样本的特征不能用向量空间来表达,则可以构成集合空间。
有监督、无监督学习
模式识别技术的核心其实是一个分类器,要实现一个好的分类器,关键是确定一个好的分类决策规则,即设计一个好的分类器模型或模式识别算法,以及确定要抽取的用于分类的样本特征。
我们经常听到的训练,学习的意思是:在已经确定分类器模型和样本特征的前提下,通过算法来处理大量训练数据来找到最优参数的过程。
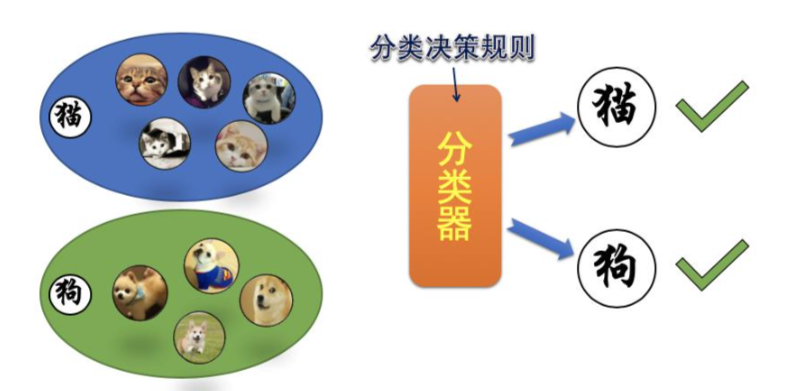
那什么是有监督学习呢?有监督的意思是存在人工干预,比如人为的给一个样本加上小狗的标签,另一个样本加上小猫的标签,然后让分类器分别在这两个样本上训练,训练完成后给定两个样本之一,分类器能够识别样本图片中是小狗还是小猫。
而无监督学习更好理解:就是把小猫和小狗 2 类样本混在一起,不人为设置标签,完全让算法自行分类,即无人工干预,而是自主地从数据代表的自然规律中学习类别划分。
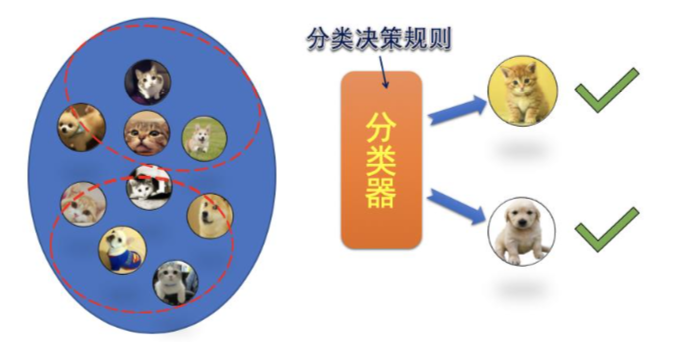
无监督学习相比有监督学习具有更高的智能水平,是未来模式识别发展的主要方向。
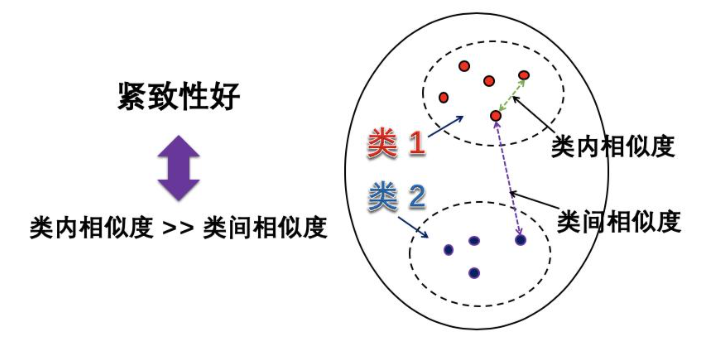
紧致性、维数灾难
紧致性:这个特性可以作为判断样本优劣性的一个指标,紧致性好的样本,类内相似度远大于类间相似,分类的裕量越大,错误率也越小。
比如:猫或狗的类内样本很相似,但 2 个样本之间相似度很低,因为猫和狗特征相差比较大。
泛化能力、过拟合
- 泛化能力:用已知样本训练好的分类器对未知样本的适应能力称为泛化能力。
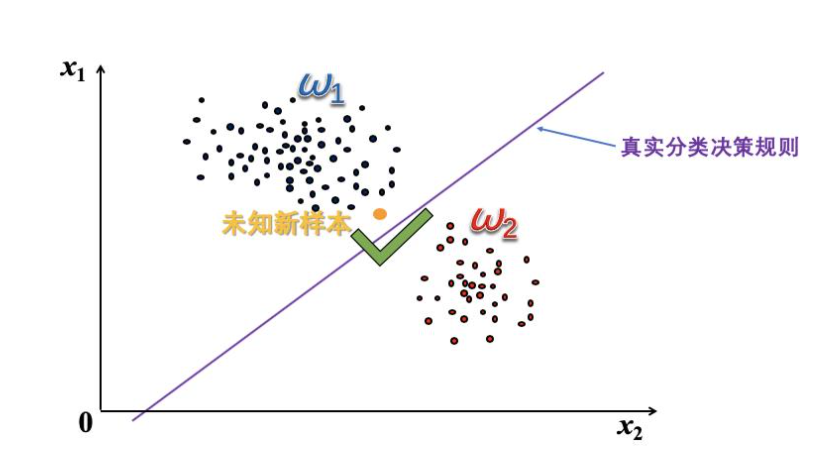
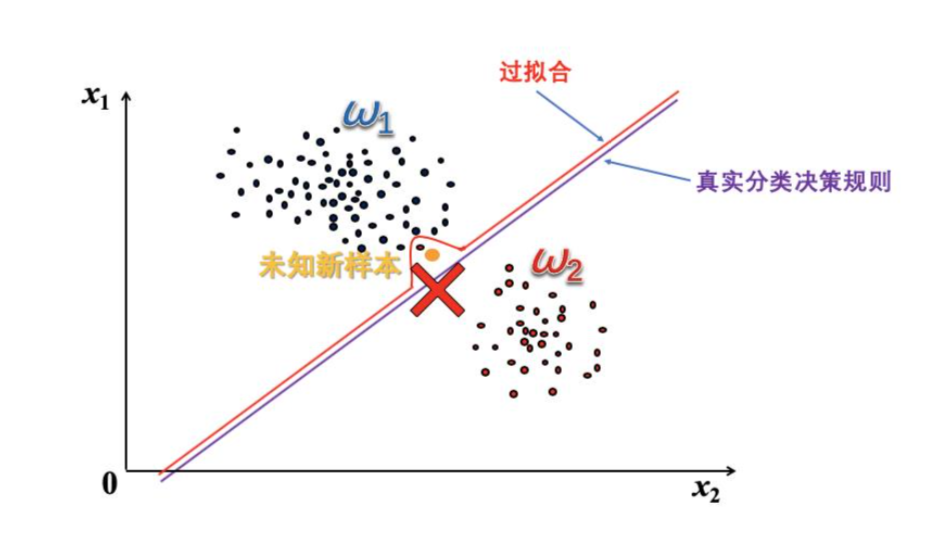
- 过拟合:要求训练的分类器能够正确分类所有样本,过分地追求分类的正确性,导致分类器的泛化能力降低,就称为过拟合。
模式识别系统
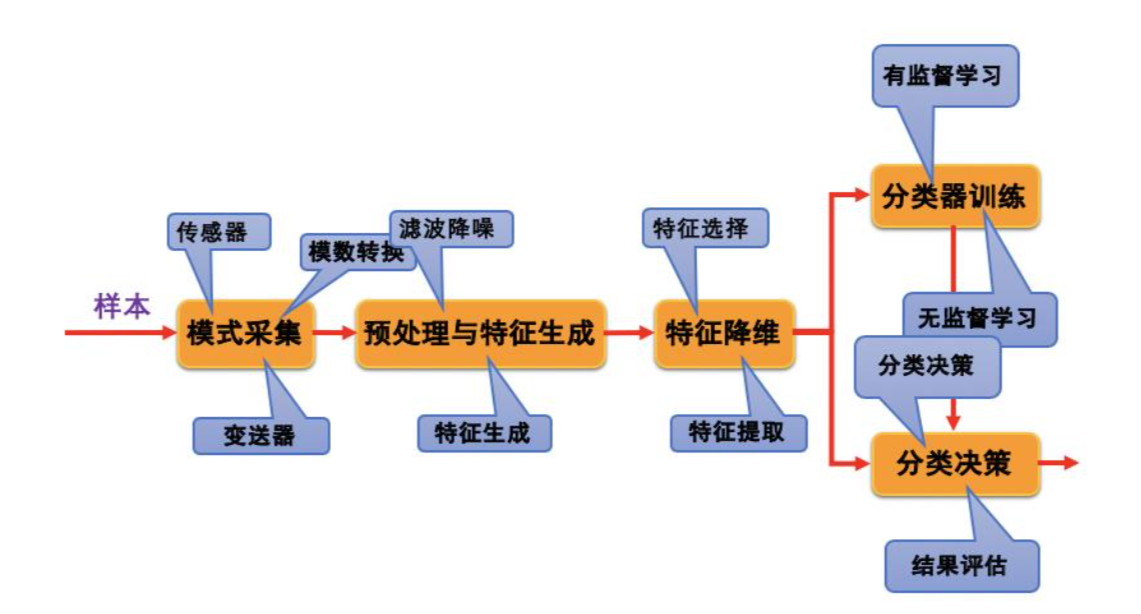
这是模式识别系统的框架,分类器的训练和对应的数学算法是整个框架的核心,下面分别简单介绍下每个步骤。
1、模式采集
模式采集的作用主要是将外部事物的各种信息转换为计算机能够处理的数据值,常见的步骤有:采集传感器模拟信号 -> A/D 转换 -> 计算机能处理的数字信号。
最常见的就是计算机处理相机拍摄的图片 - 图像处理领域。
2、预处理
通常采集的传感器数据都会包含干扰和无用数据,预处理过程的作用就是通过滤波等方法来去除干扰等噪声,并增强样本有用的分类特征。
3、特征降维
通过模式采集和预处理后样本的特征数量很多,如果选用所有的样本特征用于分类,那么算法的复杂度会很高,性能也不一定好。因此,我们可以从大量的特征中选择对分类最有效的有限个特征,即减少特征的数量,就是特征降维。
特征降维主要有 2 种方法:
- 特征选择:从已有的特征中选择一组用于分类的特征,摒弃其他特征。
- 特征提取:对原始的高维特征进行映射变换,生成一组维数更少的特征。
4、分类器设计
分类器的设计过程可以说是分类自主学习的过程,或者说对分类器进行训练,常见的有 2 种学习方法,前面也提到过:
- 无监督学习:人们没有为样本提前分类,由分类器完全自主进行训练,分类。
- 有监督学习:人们提前为样本分好类,设置了类别标签,分类器在一个已知类别的样本中学习样本特征,再进行对未知样本的分类。
简单来说:就是一个完全自主,一个需要人为干预。
5、分类决策
分类决策是对待分类的样本按照已经建立起来的分类决策规则进行分类,并且评估分类的结果。
本文原创首发于微信公号「登龙」,分享机器学习、算法编程、Python、机器人技术等原创文章,扫码即可关注!

DLonng at 11/07/19