
机器学习相关论文阅读笔记
最近看了一篇伪雷达论文,里面有些机器学习的概念不是很懂,这里记录下学习笔记。
1 端到端深度学习
传统的机器学习流程通常由多个独立模块串行组成,每个独立模块单独完成一个任务,前一个模块的结果会影响下一个模块,而使用神经网络的深度学习模型,中间的所有操作都在神经网络内部执行,不再分为多个独立的模块处理,这就称为端到端(end-to-end)。
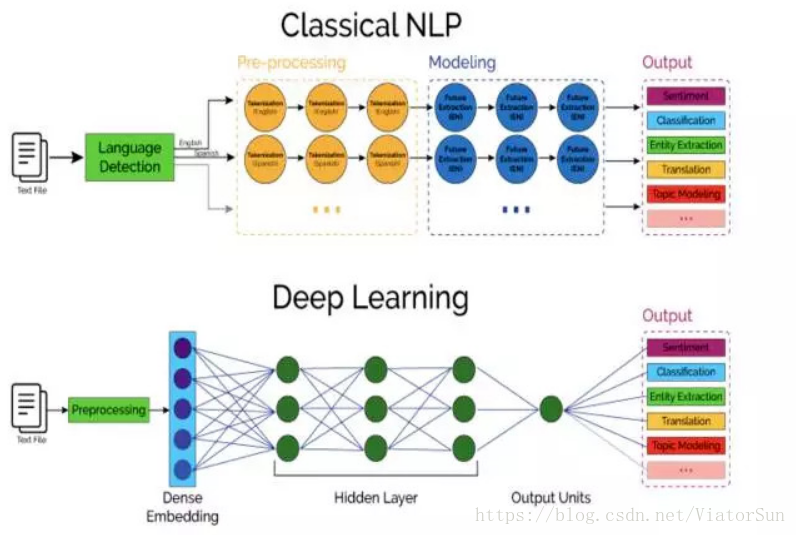
可以把 end-to-end 理解为一个函数黑盒,由输入数据直接得到输出数据,下面是一个自然语言处理问题中传统机器学习和端到端深度学习的比较(图片来自 CSDN @ViatorSun):
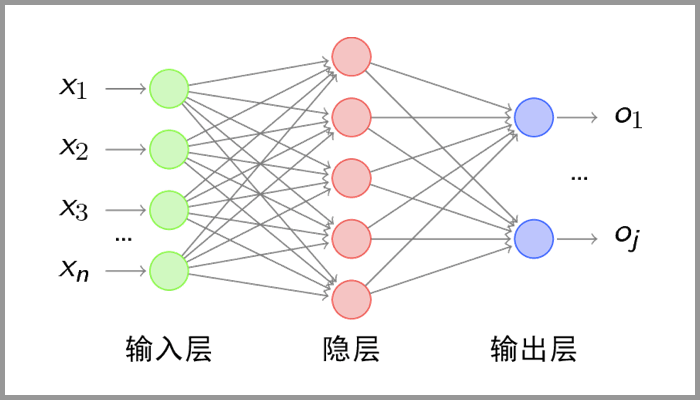
2 神经网络
这篇博客讲的非常好,很适合入门:从神经元到深度学习,我摘取了一些关键性的内容。
一个单独的神经元模型:
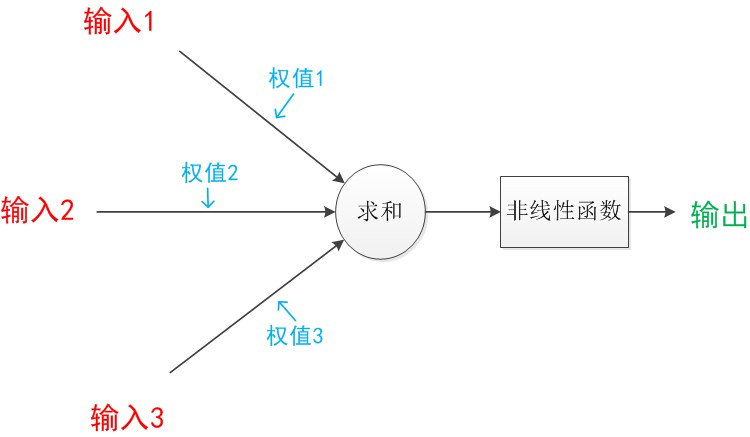
- 一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
- 神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系,理论证明两层神经网络可以无限逼近任意连续函数。
- 初学者可能认为画神经网络的结构图是为了在程序中实现这些圆圈与线,但在一个神经网络的程序中,既没有「线」这个对象,也没有「单元」这个对象,实现一个神经网络最需要的是线性代数库。
- 隐藏层的作用:从输入层到隐藏层时,数据发生了空间变换,因为矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换。隐藏层参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分,从而两层神经网络可以处理非线性分类任务。
- 两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数。因此,多层的神经网络的本质就是复杂函数拟合。
- 在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配,而中间层的节点数,却是由设计者指定的,主要凭借经验确定(网格搜索法)。
- 机器学习模型训练的目的,就是使得参数尽可能的与真实的模型逼近。
- 深度学习:多层神经网络
- 多层神经网络中的层数增加了很多,增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
- 神经网络强大预测能力的根本,就是多层的神经网络可以无限逼近真实的对应函数,从而模拟数据之间的真实关系。
- 感知器 = 神经网络,loss function = cost function = error function,active function = transfer function,权重 + 偏置 = 参数
3 卷积神经网络 CNN
受到人类视觉系统的启发,人们发明了 CNN (图片@easyai.tech):
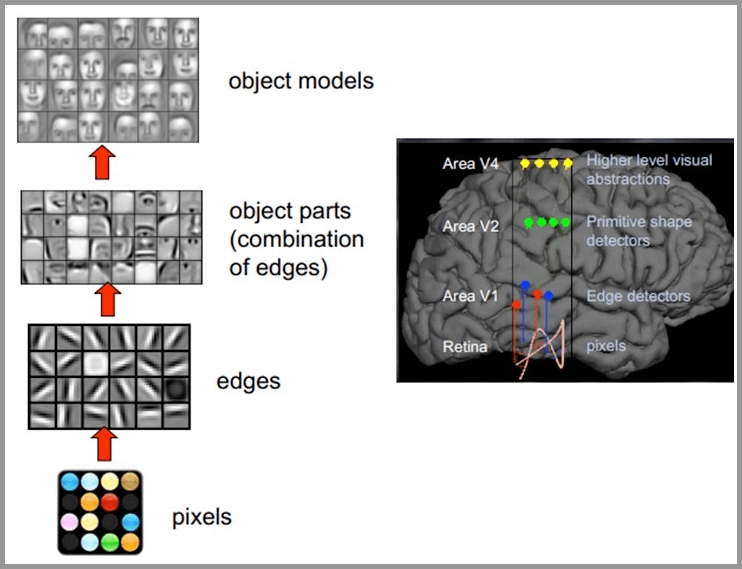
CNN 擅长处理图片,有 2 个特点:
- 能够将大数据量的图片降维成小数据量
- 能够保留图片特征,符合图像处理的原则
这两个特点也是之前人工智能处理图像的 2 个难点,现在有了 CNN 可以很好的解决,CNN 建立在前馈神经网络模型上,将其中的隐藏层换成了:
- 卷积层(Convolution Layers):提取特征
- 池化层(Pooling Layers):数据降维
- 稠密层(Dense Layers):输出结果
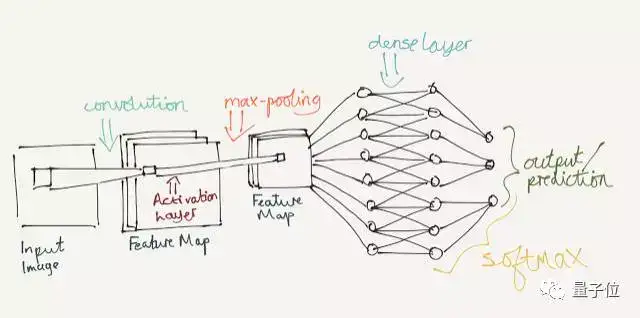
图片来自知乎:@量子位
3.1 卷积层
卷积就是用卷积核在图像上滑动,来提取图像特征,类似人眼的特征提取:

一副图像可以使用多个卷积核提取特征,卷积核的数量就可以代表所提取图像的底层纹理模式,比如使用 25 个卷积核提取一副图像的特征,则表示用这 25 种底层特征就能描绘一副图像。

3.2 池化层
池化层的作用是降低图片像素数据量,防止过拟合,降维过程可以用下面 2 个图概括(@量子位):

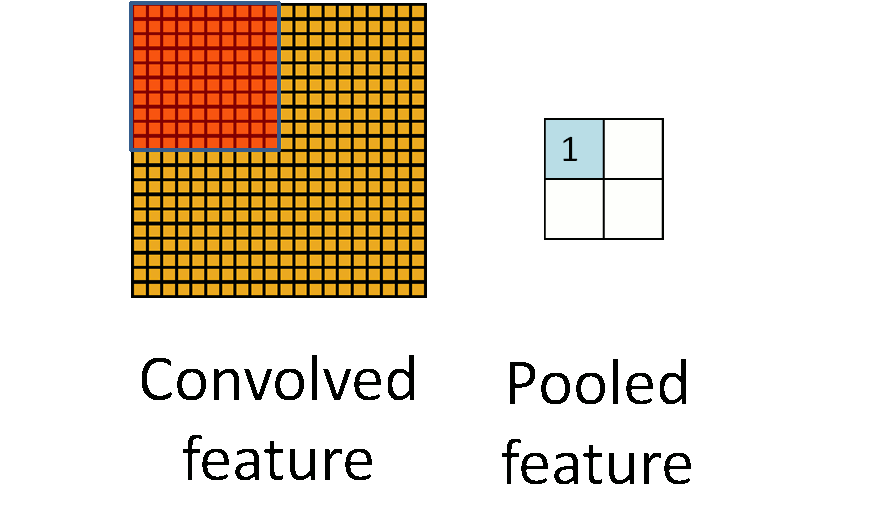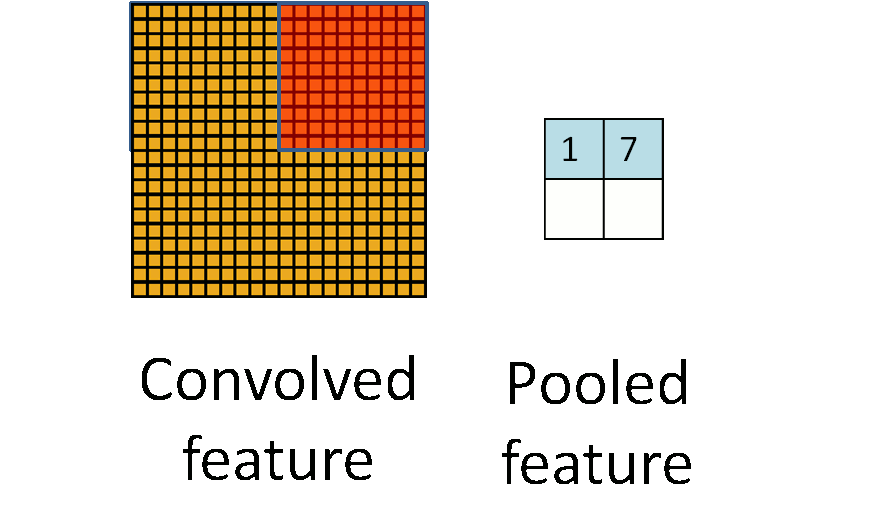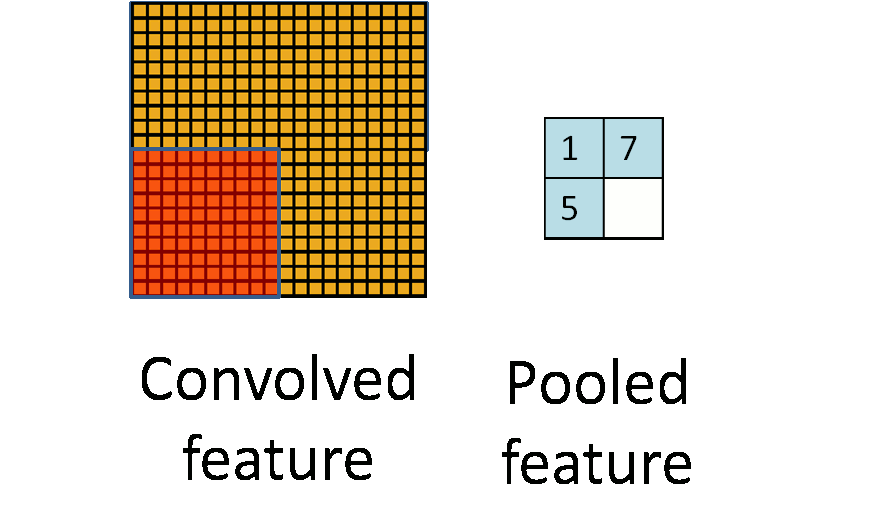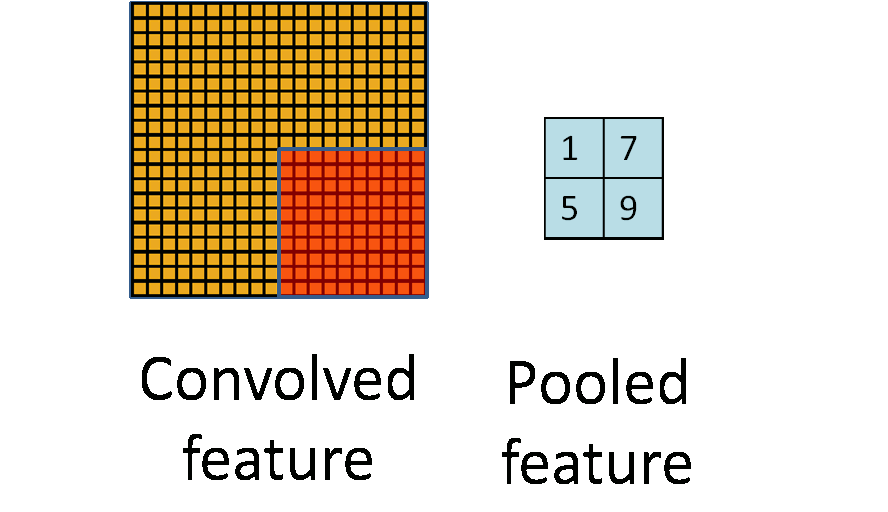
常用最大池化(Max-Pooling),意思是用一个最大值表示一个网格。
3.3 稠密层
稠密层主要用来计算最后结果,就是前馈神经网络:
CNN 常见应用:
- 图像分类,检索
- 人,车等目标检测
- 目标分割
- 人脸识别
- 等等…
参考博客:
4 损失函数
我参考的这篇博客:机器学习 - 损失函数
cost funstion 或 loss function 用来估计你的机器学习模型的预测值 Yp 与真实值 Yr 不一致的程度,它是一个非负实值函数,损失函数越小,说明模型的鲁棒性就越好,在神经网络训练参数中,通过最小化损失函数来确定合适的模型参数。
常用的损失函数:
- 对数损失函数
- 平方损失函数
- 指数损失函数
- Hinge 损失函数(SVM)
5 图像卷积
图像卷积要利用一个二维滤波器矩阵(卷积前进行 180 度翻转),称为卷积核,用该卷积核在二维图像上滑动,并计算卷积核和对应领域的乘积作为一次卷积结果,重复这个过程,完成二维图像的卷积,LeetCode 上有图像卷积的算法题。

第一个元素卷积后的结果是 -13。
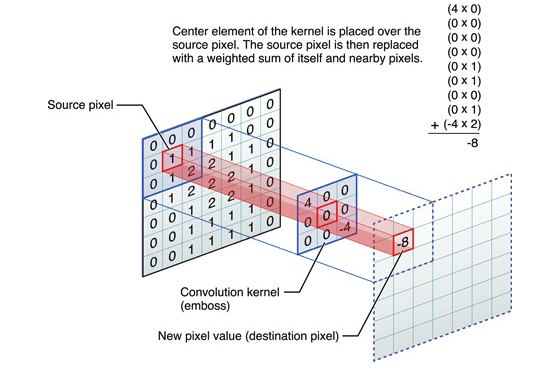
元素 1 的卷积结果为 -8。
这个卷积过程没有对所有元素进行,所以卷积后的图像变小了,但是卷积的过程是相同的。图像卷积可以对图像进行锐化,边缘检测,浮雕化,模糊等操作。
图片来自:图像卷积
6 深度图
深度图像(depth image) 也被称为距离影像(range image),是指将从图像采集器到场景中各点的距离(深度)作为像素值的图像,它直接反映了物体可见表面的几何形状。深度图像经过坐标转换可以计算为点云数据,有规则及必要信息的点云数据也可以反算为深度图。

在表达方式上,许多文献都不同,但含义都一样:
- depth image
- range image
- 3D image
- 2.5D image
- 3D data
- xyz maps
- dense-depth map
- dense-range map
深度图像的获取方法有激光雷达深度成像法、计算机立体视觉成像、坐标测量机法、莫尔条纹法、结构光法等等。
7 立体视觉深度估计
深度估计是指:从 2D 图片 img 中用函数 F 估计对应其深度图 map = F(img)。如果从单张图片中估计每个像素的深度,相当于在 2D 空间估计 3D 空间,在单目相机中只能使用单目估计,效果不是很好(不使用深度学习方法)。
目前更加侧重于立体视觉(Stereo Vision)深度估计,就是用双目立体相机模仿人眼来进行深度估计,因为有多个角度的图片就能估计出视差的变化,从而求出深度值。
本文原创首发于微信公号「登龙」,分享机器学习、算法编程、Python、机器人技术等原创文章,扫码即可关注!

DLonng at 03/17/20